In today's interconnected digital landscape, APIs serve as the backbone of modern applications. They enable seamless communication between different software components, making them crucial for delivering smooth user experiences. However, with this increased reliance on APIs comes the need for robust monitoring. API monitoring is not just a nice-to-have feature—it's an essential practice for maintaining high-performing, reliable applications. This guide will walk you through the ins and outs of API monitoring, helping you understand its importance and implementation strategies.
What is API Monitoring and Why is it Crucial?
API monitoring is like keeping a pulse on the lifeline of modern applications—it ensures APIs perform, stay available, and behave as expected. As essential connectors powering microservices, user experiences, and third-party integrations, APIs need constant oversight to catch issues like errors, slowdowns, or security glitches before they ripple out and affect services, customers, or partners. Unlike API testing, which helps during development, monitoring steps in during production, reducing downtime and speeding up fixes by analyzing real-time data and sending alerts the moment something’s off. It’s the safety net that keeps your application running smoothly.

Once an API is made public or shared with developers, its performance becomes critical, as changes or deprecations can cause widespread, unpredictable failures across applications. Ensuring stability involves managing factors like server load, data handling (e.g., paged results), encryption, and controller code quality. While thorough testing is essential before deployment, real-world usage often reveals unforeseen issues, making ongoing API monitoring crucial to catch and address problems as they arise.
Key Benefits of Implementing API Monitoring
Implementing a robust API monitoring strategy offers numerous advantages:
- Early Issue Detection: API monitoring helps detect performance issues before they affect users. With fully automated checks running as frequently as every 30 seconds, businesses can quickly identify and resolve incidents, minimizing user impact and maintaining service reliability.
- Faster Incident Resolution: Monitoring provides detailed insights into API performance, enabling quicker troubleshooting. By setting up alerts for predefined thresholds like high error rates or slow response times, teams can receive timely notifications and take immediate action when anomalies arise.
- Enhanced Security: Continuous monitoring helps identify vulnerabilities and respond to security threats like unauthorized access, injection attacks, or data leaks. This includes detecting unusual traffic patterns, enforcing rate limits to prevent abuse, and ensuring compliance with standards like OAuth, JWT, and regulations such as GDPR.
- Improved Capacity Planning: API usage patterns provide valuable insights for resource allocation, helping businesses plan capacity effectively to meet current and future demands.
- Better Third-Party API Management: Monitoring external APIs your application relies on, such as payment gateways or analytics tools, ensures their performance aligns with user expectations. It also aids in holding vendors accountable during downtime and communicating incidents to users, even when public status pages are available.
- Measuring SLA Adherence: Service Level Agreements (SLAs) are critical in enterprise software offerings. Vendors can leverage uptime data to demonstrate adherence to SLAs, while clients can use the same data to claim penalties for non-compliance, ensuring accountability on both sides. Uptime monitoring helps vendors show they are meeting their SLAs, while clients can use it to ensure they get compensation if service levels fall short.
API Monitoring: How does it work?
Consider a real-world scenario: Just like this year Delhi’s air quality took a hit, with smog covering the city and causing health problems—so checking the AQI before heading out has become a must. You have an API that provides the Air Quality Index (AQI) and pollution level for a city so, when you send a request like:
GET /air-quality?city=Delhi
The API is expected to respond with something like:
200 OK
{
"city": "Delhi",
"aqi": 310,
"status": "very poor"
}
Think of API monitoring as a robot that repeatedly "checks in" on our API to ensure it's working properly. It sends requests to the API, waits for responses, and verifies that everything is functioning as expected.
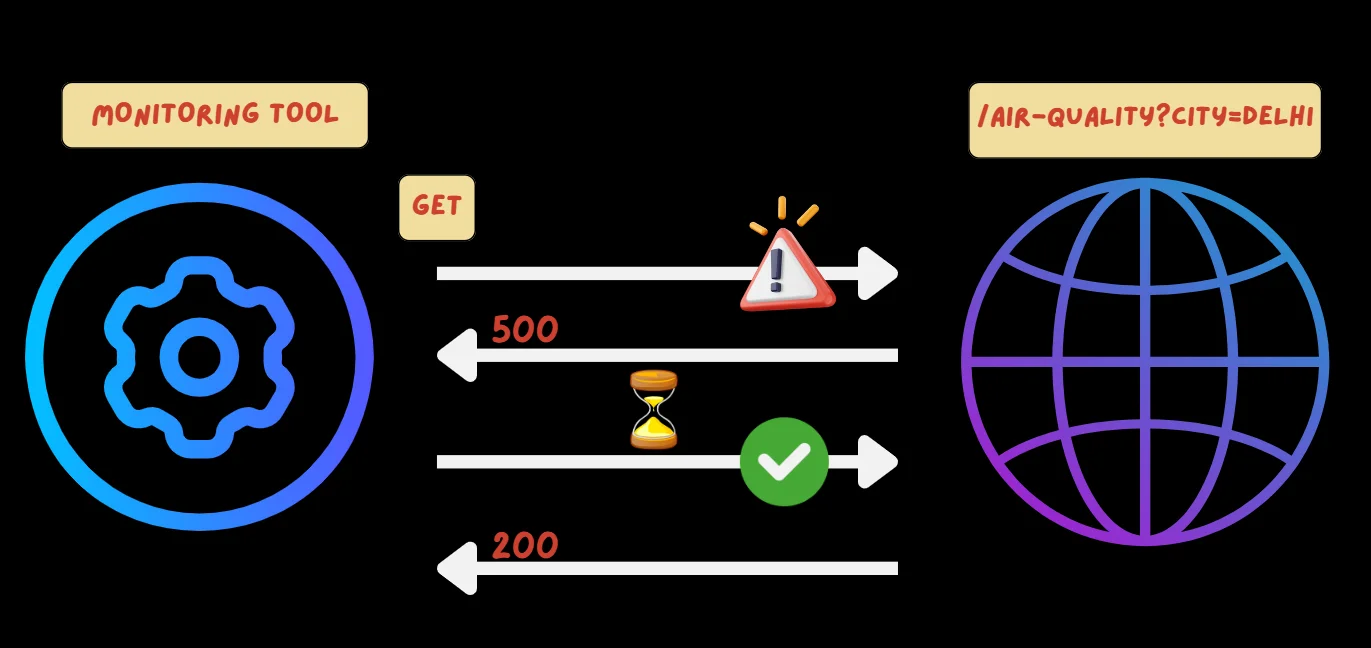
- Setup Monitoring: You configure a monitoring tool to check the
/air-qualityendpoint every minute. - Send Requests: The tool automatically sends a
GETrequest to/air-quality?city=Delhi. - Validate Responses: It expects to receive a
200 OKstatus code. It also checks that the response body includes key information like"city": "Delhi","aqi": 310, and"status": "very poor". - Authentication (if needed): If the API requires a key, such as
Bearer API_KEY_123, the monitoring tool includes it in the request. - Handle Errors: If the API returns an error (e.g.,
500 Internal Server Error) or the AQI value is missing or incorrect, the monitoring tool raises an alert to notify your team. - Redirects: If the API redirects to another endpoint (e.g.,
/new-air-quality), the monitoring tool tracks the redirect and verifies the response from the new URL.
What is an API Incident?
An API incident occurs when an API service is unavailable, malfunctioning, or fails to respond within a set time frame (typically 5 seconds to 1 minute). Users encountering the API during this period may receive errors or incorrect responses. Once an issue is detected by an API monitor, it triggers incident alerts, notifying the on-call team member through channels like phone calls, SMS, or Slack.
API alerts provide details such as the failed API check, error type, and any received response. They also include actions for the on-call person, such as acknowledging the incident or viewing its details. If an alert isn't acknowledged promptly (usually within 3 minutes), it escalates to the next person on the on-call schedule. The incident resolution process varies by team but generally involves prompt acknowledgment (measured as TTA or MTTA), collaboration, clear communication, and post-incident analysis to prevent recurrence.
Essential Metrics to Track in API Monitoring
To monitor APIs effectively, focus on key performance indicators (KPIs) that reveal their health and performance. APIs generate various signals that provide critical insights, but it's equally vital to select a monitoring tool that offers a comprehensive performance overview while allowing you to filter data by facets like request name, region, and environment to pinpoint issues. The most crucial metrics to track include:
| Metrics | Description | Key Measurements |
|---|---|---|
| Response Time | Monitoring helps you ensure that APIs respond within acceptable time limits. Slow APIs can impact user experience and overall system performance | • Average response time |
| • Minimum and maximum response times | ||
| • Response time percentiles (e.g., 95th percentile) | ||
| Error Rates | There are many types of API errors and reasons they might occur, but a sudden spike in the number or percentage of errors indicates that the API is not broadly available to its users. | • Percentage of failed requests |
| • Types of errors encountered (e.g., 4xx, 5xx status codes) | ||
| Throughput | Monitoring throughput helps you understand how many requests your APIs can handle. It guides capacity planning and scaling decisions. | • Requests processed per second |
| • Total number of requests over time | ||
| Availability | API monitoring ensures that API-connected resources are accessible, functioning correctly, and responding to calls. It also tracks the availability of dependent resources, alerting administrators to issues in the dependency chain so IT teams can act promptly to keep applications online. | • Uptime percentage |
| • Frequency and duration of outages | ||
| Latency | Latency measures the time taken for a request to return a response and serves as a key performance indicator for APIs. Teams should track latency for individual requests and overall workflows. If a frequently repeated request shows high latency, consider using caching or optimizing database queries. For increased workflow latency without specific outliers, scaling servers or database instances may be necessary. | • Time taken for data to travel between client and server |
| • Network latency vs. processing time |
Advanced API Monitoring Metrics
As your API monitoring matures, it’s time to go beyond the basics and focus on metrics that provide deeper insights into performance and user experience. Let’s break down some key advanced metrics worth tracking:
API Versioning and Deprecation:
APIs evolve, and it’s crucial to know how different versions are being used. Are users sticking to the latest version, or are they relying on outdated endpoints? Monitoring API version usage helps you decide when it’s safe to deprecate older versions without disrupting users. For deprecated endpoints, keeping an eye on traffic ensures you can communicate effectively with users who need to migrate.
Geographic Performance:
Not all regions experience your API in the same way. Factors like server locations, local internet infrastructure, or even time zones can impact response times. Monitoring geographic performance helps identify regions that need optimization or additional resources, like a new data center, to improve the user experience.
Third-party API Dependency:
Many modern applications depend on external APIs, whether for payment gateways, analytics, or recommendations. Tracking the availability and performance of these APIs is essential because their issues can directly affect your app. If a third-party API slows down or goes offline, monitoring ensures you can respond quickly—whether that’s switching to a backup or notifying users of a temporary disruption.
Rate Limiting and Quota Usage:
APIs often enforce limits to prevent overuse or abuse. Monitoring these limits helps ensure your application stays within quotas while maintaining smooth operations. This metric is particularly important for high-traffic apps or integrations where exceeding limits could result in rejected requests or additional charges. Understanding how close you are to the edge allows you to adjust usage patterns or plan for increased capacity.
How to Set Up Effective API Monitoring
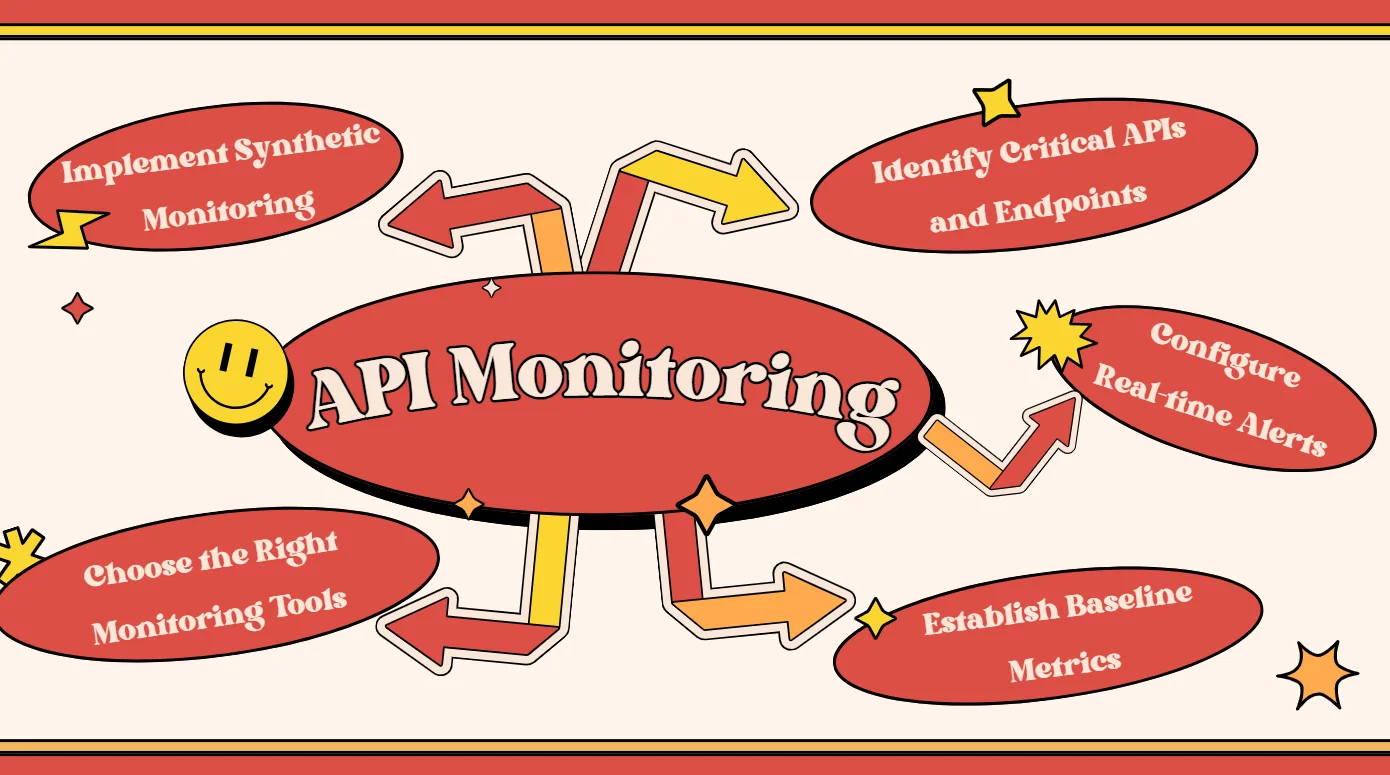
Setting up API monitoring requires a strategic approach. Follow these steps to establish an effective monitoring system:
Identify Critical APIs and Endpoints
Not all APIs are created equal, so start by identifying the ones that matter most to your business. Think about which APIs power your core functionalities or are used most often by your users. These should be your top priority. By focusing on the APIs that have the highest impact, you can ensure your monitoring efforts are directed where they’re needed most.
Establish Baseline Metrics
Before setting thresholds or creating alerts, we need to know what “normal” looks like. It’s recommended to spend some time gathering performance data on your APIs—things like average response times, error rates, or traffic patterns. These baselines will help us recognize when something is off and make our monitoring more accurate and meaningful.
Implement Synthetic Monitoring
Synthetic monitoring involves creating automated scripts that simulate API calls. These tests run on a schedule, checking if our APIs are responding as expected. It’s like having a virtual user constantly testing our system, helping us catch problems before they impact real users.
Configure Real-time Alerts
When something goes wrong, you don’t want to find out hours later. Set up alerts that notify your team the moment an API starts behaving abnormally. Tailor your alerts so they’re relevant and actionable, ensuring the right people get notified—and avoid drowning your team in unnecessary noise.
Choose the Right Monitoring Tools
When choosing the right API monitoring tool, prioritize ones that integrate seamlessly into your CI/CD pipeline, like with Jenkins or GitHub, to automate API testing and monitoring. Ensure that the tool respects API privacy by avoiding third-party SaaS platforms that expose security risks, especially for internal APIs. It's also beneficial to select a tool that combines both API testing and monitoring, providing an end-to-end performance evaluation. Open-source platforms like SigNoz are excellent choices, providing robust monitoring capabilities without locking you into expensive vendor contracts.
By following these steps, you'll create a robust foundation for your API monitoring strategy, enabling you to maintain high-performance APIs and quickly address any issues that arise.
Best Practices for API Monitoring
To maximize the effectiveness of your API monitoring efforts, adhere to these best practices:
- Balance Availability Monitoring with Data Reliability: API availability is a key metric in monitoring, but it’s not sufficient for transactions involving data exchange. To ensure all CRUD operations on exposed resources are functional, you need thorough testing. Synthetic monitoring with multi-step API monitors helps improve availability and data reliability, though it relies on predefined calls and may not fully reflect real-world traffic.
- Monitor Third-Party API Dependencies: Your application’s APIs may have dependencies on other internal or external APIs for processing inputs or generating outputs. While you may have established a monitoring strategy for your own APIs, it’s important to remember that the third-party APIs your application depends on might not have similar monitoring in place. To ensure everything functions smoothly, you should also keep an eye on the behavior of these dependent APIs.
- Continuous Monitoring Across Environments: API performance can vary significantly across different stages of development, and issues might arise at any point in the pipeline. To ensure consistent reliability, it's crucial to monitor your APIs in development, staging, and production environments. By doing so, you can identify problems early, before they impact users, and maintain a smooth and seamless experience throughout the entire application lifecycle.
- Integration with DevOps Workflows: The DevOps and CI/CD movement emphasizes continuous and automated testing to ensure consistent performance throughout the development lifecycle. By integrating API monitoring into your CI/CD pipelines, you can define a clear strategy for monitoring at every stage of your code release process. This allows for proactive detection of issues, faster issue resolution, and ensures that each iteration of your prototype performs optimally. Routine monitoring at regular intervals further strengthens this cycle, improving the reliability and performance of your APIs with every code update.
- Implement Monitoring as Code: Treating your monitoring configurations as code ensures that your monitoring setup is just as scalable, repeatable, and version controlled as your application code. By defining your monitoring rules in configuration files, you ensure consistency across environments, make updates easier, and enable quick rollbacks if needed. This approach also provides full traceability of monitoring changes and ensures that configurations are easily replicated in new or testing environments.
- Performance Baselining: Establishing a performance baseline is crucial for understanding what "normal" looks like for your APIs. By collecting data over time, you can set benchmarks for key metrics such as response times, throughput, and error rates. With a solid baseline in place, you’ll be able to identify deviations more quickly, spot performance degradation, and take corrective action before small issues turn into major disruptions.
- End-to-End Request Tracing: Distributed tracing allows you to track the full journey of an API request, from the initial call to the final response. This technique is especially valuable in microservices architectures, where requests often pass through multiple services. With end-to-end tracing, you can easily identify bottlenecks, failures, or delays that occur across various components, enabling you to pinpoint root causes quickly and optimize your system for better performance.
By following these practices, you'll create a robust and efficient API monitoring system that proactively maintains the health and performance of your APIs.
Common Challenges in API Monitoring and How to Overcome Them
While API monitoring is crucial, it comes with its set of challenges. Here are some common issues and strategies to address them:
| Factors | Challenge | Solution |
|---|---|---|
| High Volume of API Traffic | Processing and analyzing large volumes of API data in real-time. | Implement sampling techniques and use scalable monitoring tools designed for high-throughput environments. |
| Monitoring Microservices Architectures | Tracking API calls across distributed systems. | Utilize distributed tracing tools and implement correlation IDs to track requests across services. |
| Handling Authentication in Monitoring | Monitoring authenticated APIs without compromising security | Use dedicated monitoring accounts with limited permissions and rotate credentials regularly. |
| Balancing Comprehensive Monitoring with Performance | Ensuring monitoring doesn't impact API performance. | Optimize monitoring agents, use asynchronous logging, and carefully select metrics to track. |
| Managing False Positives | Dealing with alert fatigue from frequent false alarms. | Fine-tune alert thresholds, implement alert correlation, and use machine learning for anomaly detection. |
| Limited Downtime Cause Reporting | API monitoring only observes final outputs, lacking insights into why an incident occurred. | Supplement API monitoring with Application Performance Management (APM) or log management tools to gain deeper root cause insights into application behavior. |
By addressing these challenges head-on, you can create a more robust and efficient API monitoring system that provides valuable insights without compromising performance or security.
Leveraging SigNoz for Advanced API Monitoring
SigNoz is a comprehensive open-source Application Performance Monitoring (APM) tool designed for efficient API monitoring. It natively supports OpenTelemetry, a leading open-source standard under the Cloud Native Computing Foundation for instrumenting cloud-native applications. SigNoz excels at tracking API performance metrics and is particularly effective for applications built on microservices or serverless architectures.
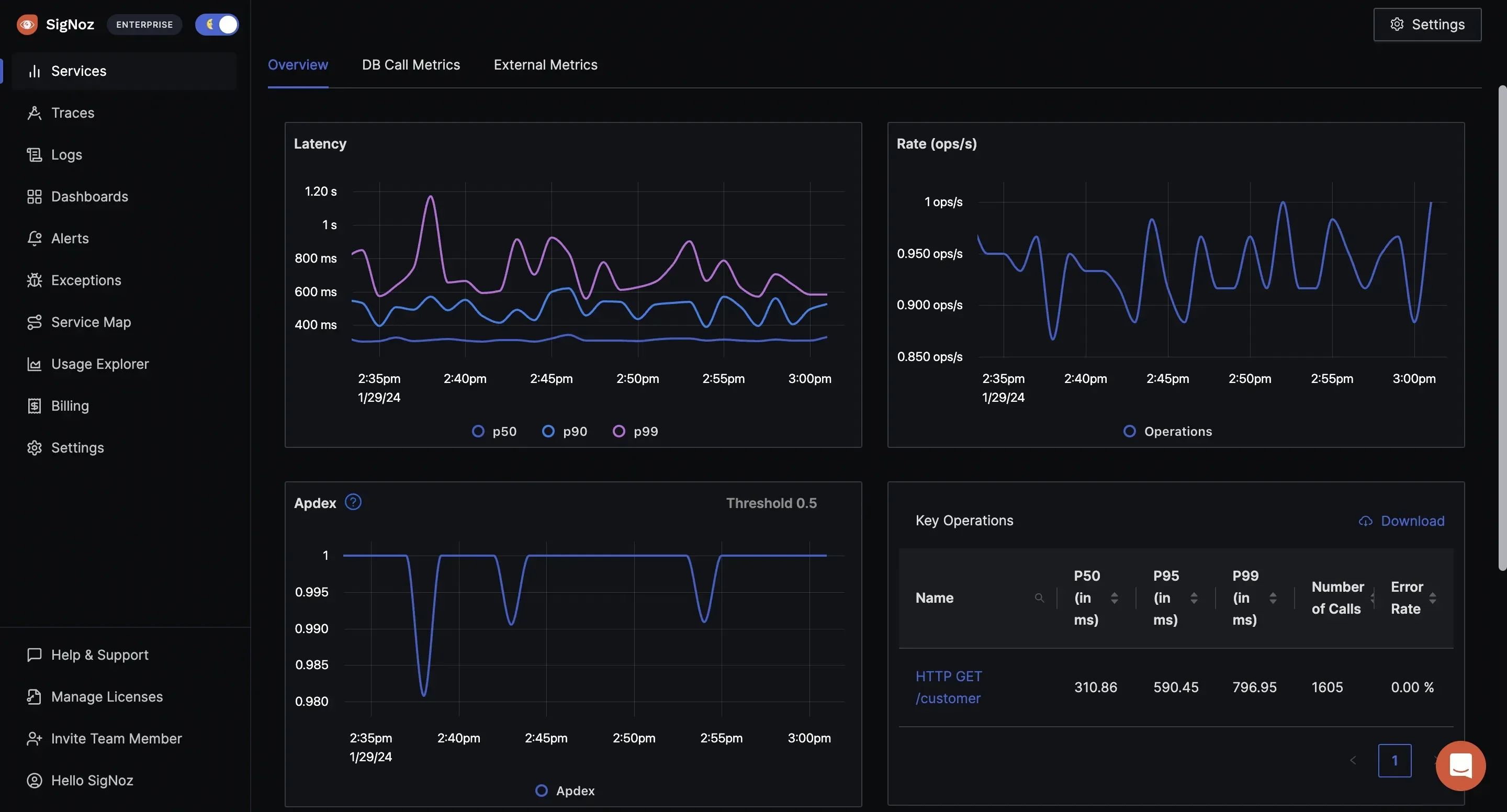
Here’s a closer look at how SigNoz empowers effective API monitoring with its robust feature set:
Distributed Tracing
Gain end-to-end visibility into your API requests by mapping their journey across microservices or serverless functions. With distributed tracing, you can identify performance bottlenecks and pinpoint issues within complex architectures. For instance, if a request slows down at a specific service, you’ll know exactly where to investigate, helping you resolve issues faster.
Real-time Metrics
Keep track of essential API performance metrics like latency, error rates, and throughput as they happen. With real-time insights, you can detect and address anomalies instantly, ensuring smooth user experiences. Whether it’s a spike in error rates or slower response times, these metrics help maintain high API reliability.
Custom Dashboards
Design dashboards tailored to your specific needs, whether it’s for different teams, services, or API groups. For example, a development team might focus on response times, while an operations team monitors uptime and error rates. This flexibility ensures each team has the insights they need without wading through irrelevant data.
Anomaly Detection
Leverage machine learning-powered anomaly detection to spot unusual API behavior before it escalates into a full-blown issue. This could mean identifying traffic patterns that don’t align with regular usage or detecting unexpected spikes in error rates. Early detection ensures teams can act proactively rather than reactively.
Alerts and Notifications
Configure alerts to notify your team when predefined thresholds are breached, like high error rates or degraded response times. These alerts can be sent via email, Slack, or other communication tools, ensuring immediate awareness. With customizable alerting rules, you can tailor notifications to match the severity of incidents, helping prioritize responses effectively.
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
Check out this video tutorial on how to do API monitoring with SigNoz:
Refer the official docs for more information.
Future Trends in API Monitoring
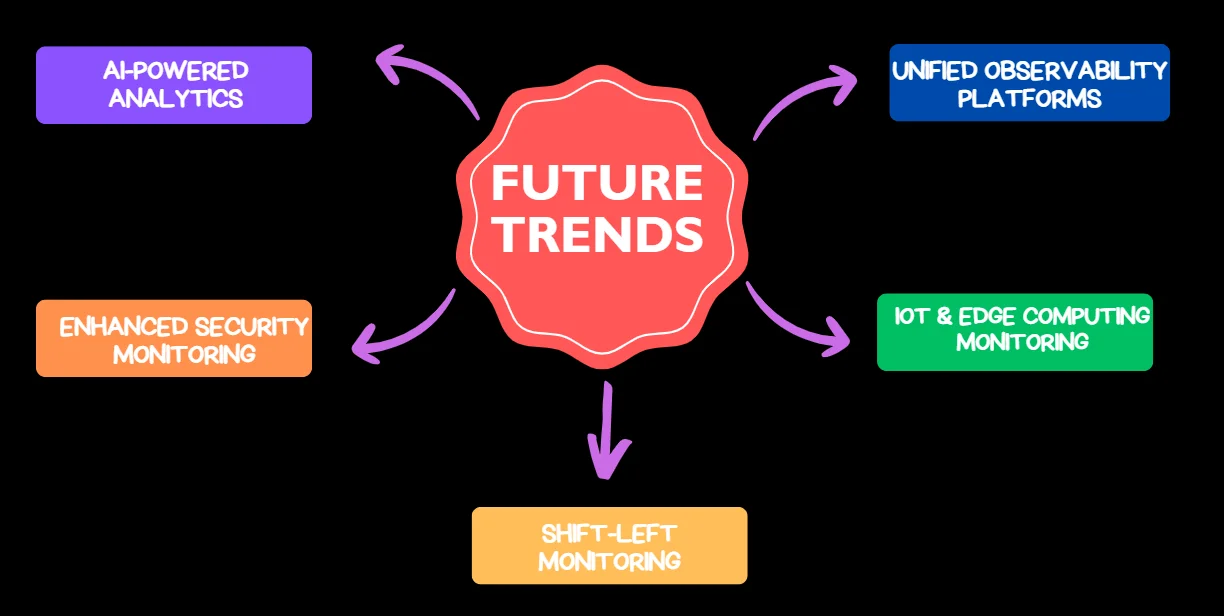
As technology evolves, so does the landscape of API monitoring. Stay ahead of the curve by keeping an eye on these emerging trends:
AI-Powered Analytics
Advanced machine learning models will transform how API issues are identified and resolved. These algorithms will not only detect anomalies but also predict potential failures before they happen. This proactive approach ensures smoother operations and reduces downtime, allowing businesses to stay a step ahead of performance hiccups.
Shift-Left Monitoring
Monitoring will no longer be an afterthought. As part of the shift-left approach, developers will integrate monitoring into the development phase, embedding observability directly into their code. This helps catch potential issues early, improving efficiency and reducing costly post-deployment fixes.
Enhanced Security Monitoring
APIs are increasingly a target for cyberattacks. Future monitoring tools will go beyond performance metrics to include sophisticated security features. These tools will monitor for suspicious activity, such as unusual traffic patterns or unauthorized access, helping to safeguard APIs from evolving threats.
IoT and Edge Computing Monitoring
With the rise of IoT devices and edge computing, APIs will operate in more distributed and latency-sensitive environments. Monitoring solutions will adapt to handle these complexities, providing visibility into devices operating on the edge and ensuring seamless communication in real time.
Unified Observability Platforms
API monitoring will become an integral part of comprehensive observability solutions, offering a unified view of application health, infrastructure, and user experience. These platforms will enable teams to correlate API performance with broader system behavior, simplifying troubleshooting and optimization efforts.
By staying informed about these trends and adapting your monitoring strategies accordingly, you'll be well-positioned to maintain high-performing, secure APIs in the ever-evolving technological landscape.
Key Takeaways
- API monitoring is essential for maintaining high-performance, reliable applications.
- Key metrics to track include response times, error rates, throughput, and availability.
- Implementing best practices like continuous monitoring and regular reviews is crucial for effective API monitoring.
- Tools like SigNoz can significantly enhance API monitoring capabilities, offering features like distributed tracing and real-time metrics.
- Future trends in API monitoring include AI-powered analytics and enhanced security monitoring.
FAQs
What's the difference between API monitoring and API testing?
API monitoring is an ongoing process of tracking API performance and behavior in real-time production environments. It focuses on ensuring APIs are functioning correctly and efficiently under actual usage conditions. API testing, on the other hand, is typically performed during development and involves validating API functionality, reliability, and security in controlled environments before deployment.
How often should I review my API monitoring metrics?
The frequency of reviewing API monitoring metrics depends on your application's criticality and update cycle. As a general rule:
- Daily: Check real-time dashboards for any immediate issues.
- Weekly: Conduct a more in-depth review of performance trends and anomalies.
- Monthly: Perform a comprehensive analysis to inform long-term optimization strategies.
For critical applications, more frequent reviews may be necessary.
Can API monitoring help with compliance and regulatory requirements?
Yes, API monitoring can significantly aid in meeting compliance and regulatory requirements. It provides:
- Audit trails of API access and usage.
- Performance metrics to ensure SLAs are met.
- Security insights to detect and prevent unauthorized access.
- Data handling information to ensure compliance with regulations like GDPR.
Ensure your monitoring solution offers features that align with specific compliance needs in your industry.
What are the key considerations when choosing an API monitoring tool?
When selecting an API monitoring tool, consider the following factors:
- Scalability: Can it handle your current and future API traffic volume?
- Integration: Does it integrate well with your existing tech stack and workflows?
- Customization: Can you tailor alerts and dashboards to your specific needs?
- Data Retention: How long does it store historical data for trend analysis?
- Ease of Use: Is the interface intuitive for both developers and operations teams?
- Cost: Does the pricing model align with your budget and expected usage?
- Security: Does it offer features to monitor and protect against API-specific threats?
- Support: Is there adequate documentation and customer support available?
By carefully evaluating these aspects, you can choose a tool that best fits your organization's API monitoring requirements.
